Anatomy of a DeFi Trading Agent (and Its Missing Layer)
We reviewed 20+ DeFi trading agents. They've all converged on the same architecture, and the same weak spot: the risk gating step between LLM decision and onchain execution. Here's the anatomy of the gap, why prompt engineering can't close it, and what an independent execution gate looks like.

The Gap Between Intent and Execution
We went through 20+ DeFi Agent repos and once you read enough DeFi agent code, a pattern jumps out. We can look at the full pipeline from pre-trade, to decision making, to the execution layer and typically its the decision layer where things tend to get lost. That gap is what this post is about. The agents we care about are the ones executing a pre-committed directive over time: yield rotators, LP managers, directive traders. Single-tick HFT-adjacent agents are a different shape entirely.

Heres the typical pattern:
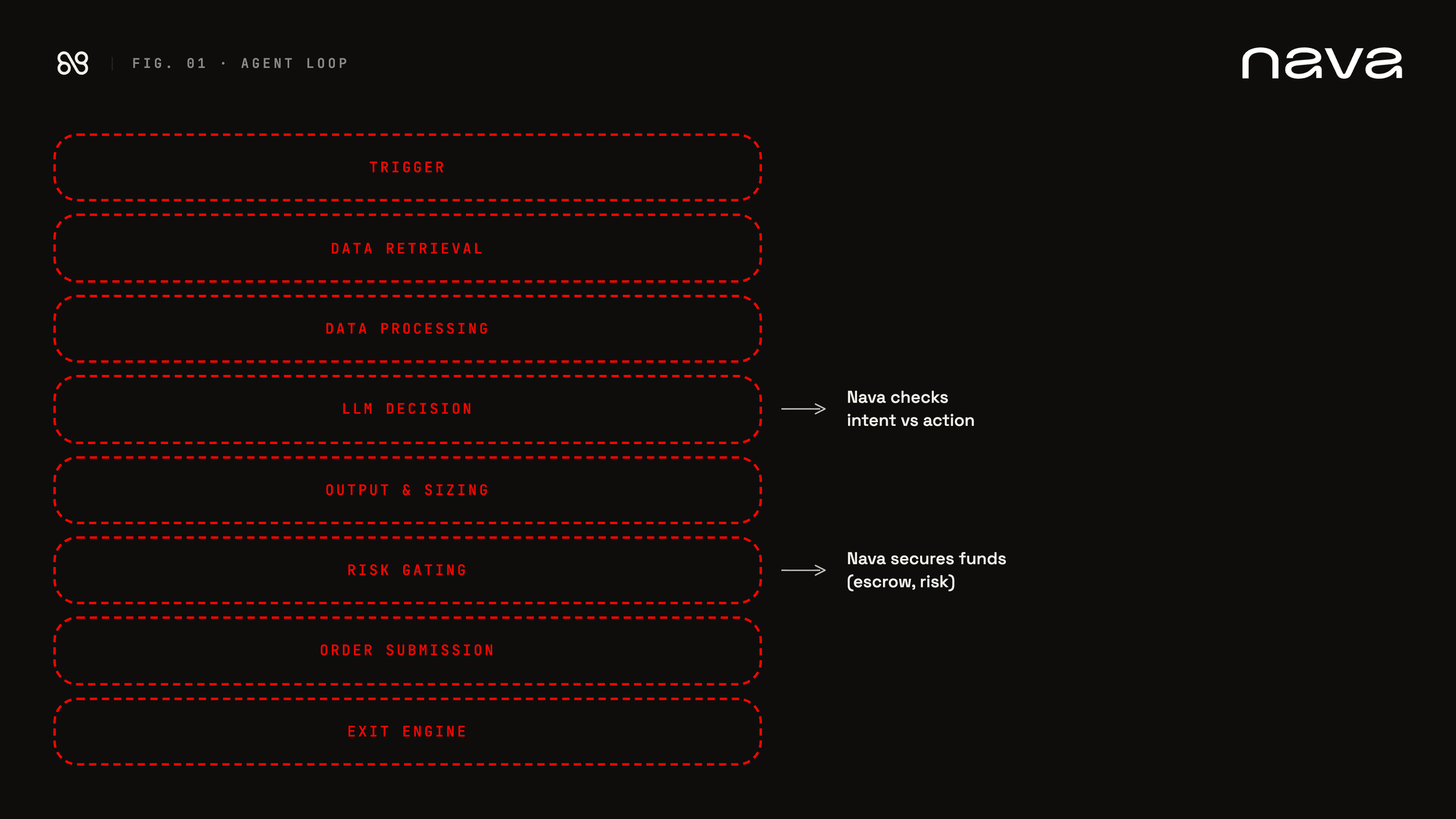
- Trigger
- The agent wakes up on a scheduled loop, a cron, or an exchange-driven event.
- Data retrieval
- The agent pulls the inputs it needs to decide. This is more sophisticated than the average outside observer gives it credit for. A working trading agent reads account state, an orderbook snapshot, OHLCV (open, high, low, close, volume) at multiple intervals, onchain pool states, and increasingly news and sentiment feeds. The variation across repos is mostly in what they fetch and at what cadence, not in how.
- Data processing
- Raw data isn't useful to an LLM. So the agent computes a feature set first. The standard set is technical: EMA, RSI, MACD, ATR, Bollinger Bands, ADX, OBV, VWAP. These are calculated deterministically and shaped into a prompt the model can read. This is also where the agent's strategy fingerprints start to show. A momentum bot keeps a different feature window than a mean-reversion one.
- LLM decision
- This is where things are generally the most varied and also the most interesting. We see at least three patterns:
- Full trade decision
- The LLM outputs a structured trade object (asset, side, size, TP/SL).
- Simple. Hard to constrain.
- Probability signal
- The LLM outputs a directional probability and a confidence score, which is then passed to a deterministic sizing algorithm.
- Kelly sizing is the most common pairing. The LLM proposes the bet, math sizes it.
- Multi-agent committee
- Several specialized agents (technical, sentiment, contrarian) vote or debate, with a structured aggregation step.
- Slow, expensive, occasionally produces uncanny consensus.
- Full trade decision
- Most production agents have moved away from "full trade decision" toward signal-plus-math. This is because LLMs are bad at numeric magnitude. They're fine at direction.
- This is where things are generally the most varied and also the most interesting. We see at least three patterns:
- Output parsing and sizing
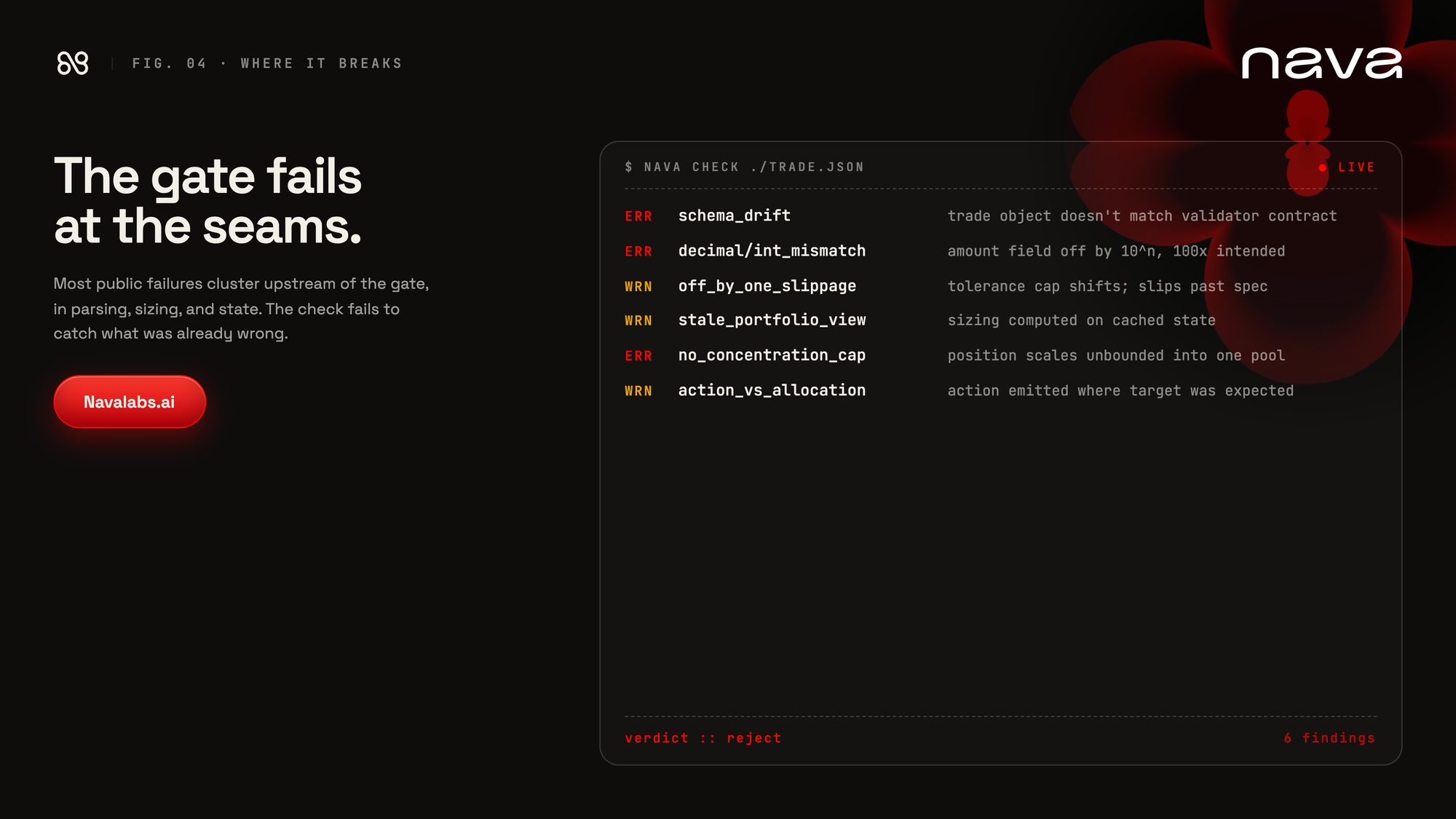
- Whatever the LLM emits gets parsed, validated against a schema, and combined with the agent's risk parameters. This is where things like position limits, leverage constraints, and minimum tick sizes get applied. It looks deterministic on paper. In practice this is also where a lot of subtle bugs live: schema drift, integer or decimal mismatches, off-by-one slippage caps. The kind of thing that doesn't surface until a transaction has already executed for 100x the intended amount.
- Risk gating
- The load-bearing step and the one most agents handle worst.
- In a traditional trading shop this would be where pre-trade risk runs: position concentration, drawdown checks, kill-switch flags, asset allow-listing, exposure caps, intent reconciliation. In most OSS agents, "risk gating" is one or two hard-coded guards (a max trade size, maybe a slippage cap) and that's the entire layer. The check is co-located with the execution path, written by the same author as the agent logic, and exercises the same blind spots.
- Across the agents we reviewed, the most common failure mode was this: the strategy looks responsible at the LLM step, and then nothing checks anything between 'model said yes' and 'transaction broadcasted. This is the gap where the public failures of the last year have lived. It's not necessarily because the model was wrong (the model usually wasn't even consulted on the part that broke) but because nothing was watching the gap between intent and execution.
- We'll come back to this.
- Order submission
- A signed transaction goes out to the venue or chain. Mechanically uninteresting. The work happens before this point.
- Agent state update
- The trade is logged, the position state updates, and in better agents something like a learnings.md file gets appended. A running journal that the agent reads back in on its next wake. It's the closest most OSS agents have come to actual continual learning. Lightweight, mostly text, and surprisingly effective at letting an agent course-correct across sessions without retraining.
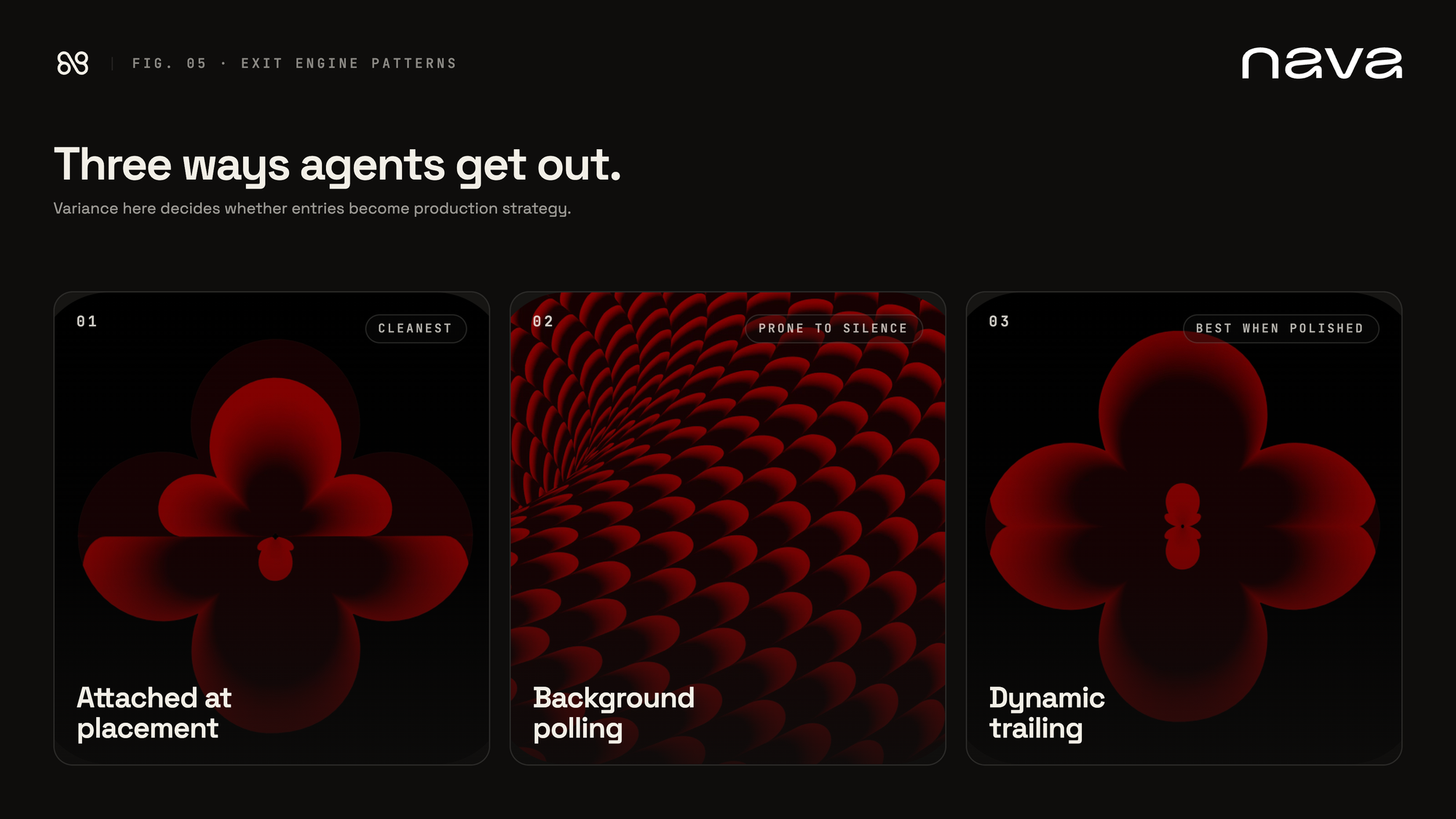
- Exit engine
- The second most under-implemented phase. Three patterns:
- Attached at placement. Take-profit and stop-loss orders are attached at order time and managed by the venue. Cleanest. Doesn't require the agent to stay awake to enforce them.
- Background polling. A side loop scans market state on a cadence and pulls positions when custom constraints are hit. More flexible, more prone to silence. The loop dies, no one notices.
- Dynamic trailing. Stop-loss adjusts upward as profit grows. Senpi has this. So do a handful of the more polished private agents we've spoken to.
- The variance here is the most consequential thing after risk gating. An agent that wins on entries but treats exits as an afterthought turns into a strategy that gives back its gains. We've seen this pattern often enough to flag it as the second-largest gap.
- The second most under-implemented phase. Three patterns:
What this tells us
Many of these phases are a commodity: trigger, data retrieval, data processing, and order submission. Implementations vary at the margin, but no one's reinventing them and few are failing at them. Agent state update is mostly bookkeeping, with the partial exception of learnings.md, which is the closest many have come to genuine cross-session learning.
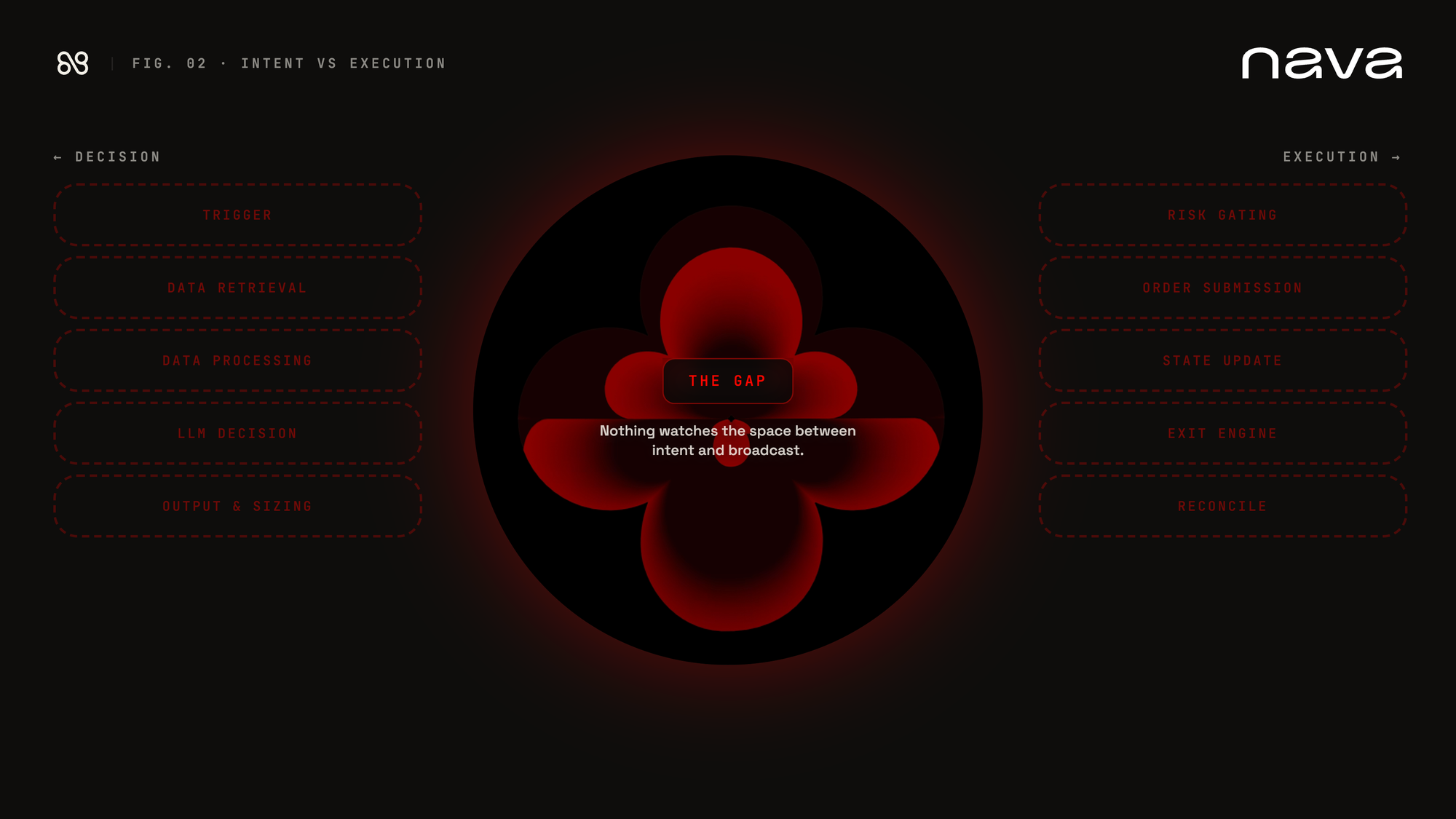
Output parsing and sizing look like they belong in that bucket. They don't. This is where most of the failures cluster: parsing breakage, schema drift, decimal/int mismatches, action-vs-allocation confusion. It's a lot of what we're building for, and we'll come back to it later.
Most of the public failures of the last twelve months have happened at the risk gating phase. The actual cause is often upstream, in state management, parsing, or sizing, and the gate just fails to catch what was already wrong. But that's the job of the gate. A trade with the wrong size or built on a stale view of the portfolio shouldn't reach a wallet, and in most of the agents we looked at, nothing is set up to stop it.
All in all, the pattern is hard to miss once you see it. Agent teams have been investing in the parts of the stack that are easiest to demo (the LLM step, the strategy) and underinvesting in the parts of the stack that determine whether the demo turns into a production system (the gates between decision and execution, and the rules that govern when to exit). We're collectively converging on a shape, and the shape has a hole in the middle.
We're sure we haven't seen everything. If you're building something that handles risk gating or exit logic differently than what we've described here, we want to hear about it — the closed-source agents we've talked to have already surprised us.
Where this points
Everything we found points to the same missing piece. That's what Nava is.
We're building the layer that sits in that gap.
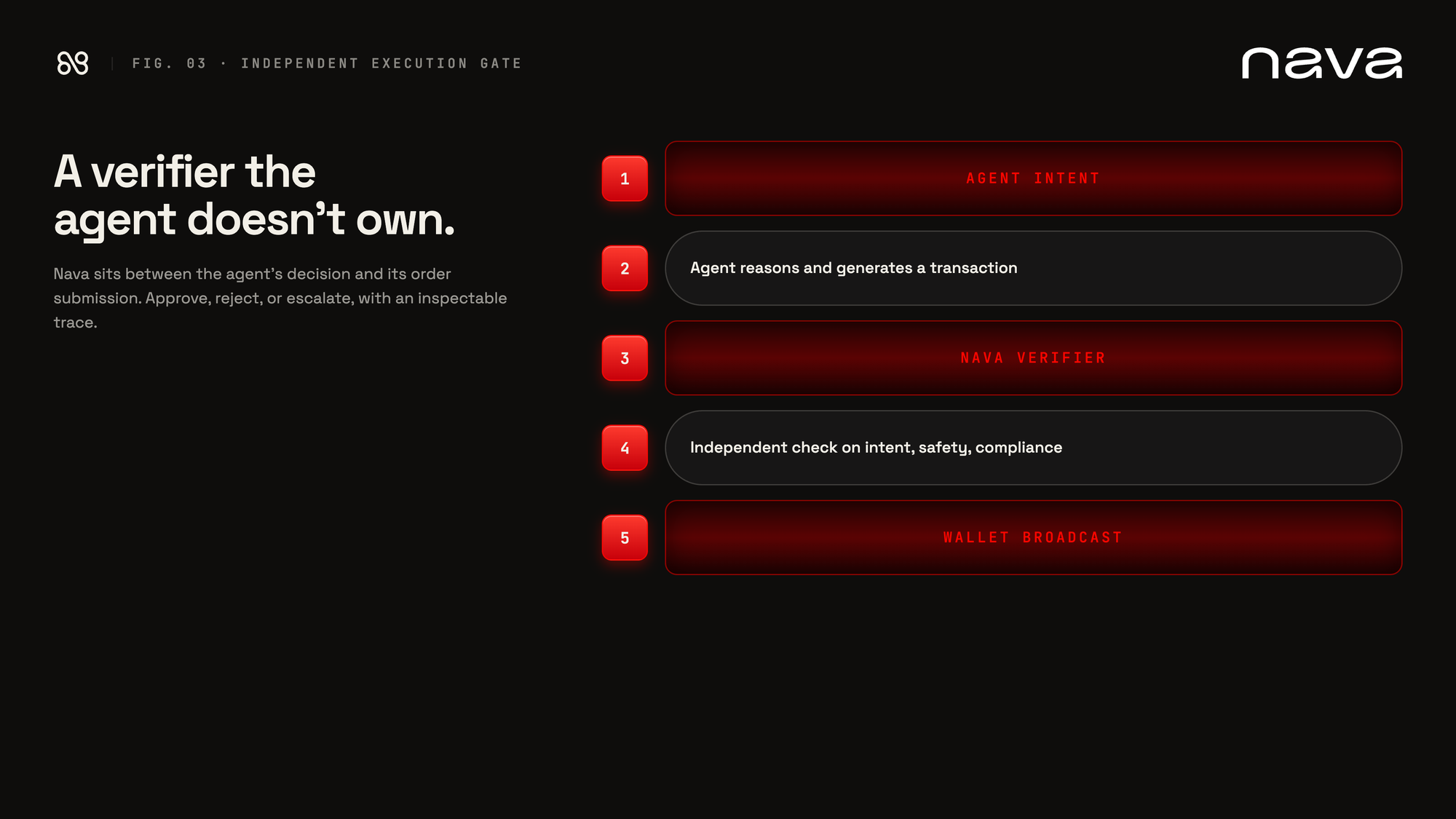
Nava is an independent execution gate. It sits between an agent's decision and its order submission. It takes the strategy and risk constraints the user has pre-committed, independently decodes whatever the agent is about to broadcast, and produces a verdict (approve, reject, or escalate to human approval) with an inspectable trace. It is the risk gating step, run by something other than the agent that authored the trade.
Constraints aren't abstract here. Position caps, allowlisted protocols, max slippage, drift from the stated allocation, action-type whitelists. Each one is a specific check the trade has to clear before it leaves the wallet.
This isn't a model problem. You can't weasel your way out of the gap between intent and execution. You can't prompt-engineer agents into checking themselves. The right shape of the fix is a verifier the agent doesn't own.
That's where we sit. In a future post we'll go deeper on the exit-engine gap, and on what closed-source DeFi agents are doing differently. Early reads suggest they handle both gates substantially better than their OSS counterparts.
The risk gate isn't the part anyone wants to build. That's exactly why it's the part that doesn't exist. We're building it. Because without proper constraints you are limited in both execution and experimentation. With our solution, going from the latest yield strategy to a production agent is becoming a lot easier.
Drop us a line:

Nava x Privy: Enabling AI Agents to Transact from Wallets Securely
Nava gives AI agents secure, scoped access to user wallets built on Privy. No app secrets, backends, or private keys. One browser-based OAuth flow spans CLIs, MCP servers, and skills, so agents transact autonomously within boundaries we control.
Auditable LLM Arbiter for DeFi Security
The gap between what you tell an agent and what it actually executes onchain is real, exploitable, and unsolved. Nava's Arbiter combines deterministic rules with semantic reasoning to verify intent-to-transaction alignment before funds move. Peer-reviewed at NDSS 2026.
Nava AI | Trust Infra for the Agentic Economy
AI agents are trading, lending, and staking with real money, unverified and unaccountable. Nava's verification layer sits between every agent decision and onchain execution, catching intent misalignment, parameter errors, and adversarial inputs before funds move. Read the full whitepaper.